Common Machine Learning Algorithms for Classification
Machine learning algorithms for classification enable computers to automatically classify and categorize data into predefined classes or categories. These algorithms analyze input data, learn from it, and then make predictions or assign labels to new data based.
Here we’ll cover 7 machine learning algorithms for classification.
What is Classification?
It is a process of forecasting the class of given data points. Classification belongs to a supervised machine learning category where the labeled dataset is used. We must have input variables (X) and output variables (Y) and we applied an appropriate algorithm to find the mapping function (f) from input to output. Y = f(X).
Basic Terminologies
Before discussing the machine learning algorithms used for classification, it is necessary to know some basic terminologies.
- Classifier: It is an algorithm that maps the information to a particular category or class.
- Classification model: It attempts to make some determination from the input data given for preparing. It will anticipate the class names/classifications for the new information.
- Feature: It is an individual quantifiable property of a wonder being watched.
- Binary Classification: In binary classification, there are two possible results, for example, gender classification into male and female.
- Multi-class classification: In multi-class classification, there are more than two classes where each sample is assigned to one and only one objective mark. For example, fruit can be mango or apple yet not both simultaneously.
- Multi-label classification: In multi-label classification, each sample is mapped to a lot of target labels or more than one class. For example, a research article can be about computer science, a computer part, and the computer industry simultaneously.
Examples of Classification Problems
Some common examples of classification problems are given below.
- Natural Language Processing (NLP), for example, spoken language understanding.
- Machine vision (for example, face detection)
- Fraud detection
- Text Categorization (for example, spam filtering)
- Bioinformatics (for example, classify the proteins as per their functions)
- Optical character recognition
- Market segmentation (for example, forecast if a customer will respond to promotion)
Machine Learning Algorithms for Classification
In supervised machine learning, all the data is labeled and algorithms study to forecast the output from the input data while in unsupervised learning, all data is unlabeled and algorithms study to inherent structure from the input data.
Some popular machine learning algorithms for classification are given briefly discussed here.
- Logistic Regression
- Naive Bayes
- Decision Tree
- Support Vector Machine
- Random Forests
- Stochastic Gradient Descent
- K-Nearest Neighbors (KNN)
1. Logistic Regression
Logistic regression is a statistical modeling technique used for binary classification tasks. It is commonly used when the goal is to predict a binary outcome, where the dependent variable can take one of two possible values, such as “yes” or “no,” “true” or “false,” or 0 or 1.
The logistic regression algorithm models the relationship between the independent variables and the probability of the binary outcome. It estimates the probability of the outcome using a logistic function, also known as the sigmoid function. This function maps any real-valued input to a value between 0 and 1 and represents the probability of the positive class.
The algorithm works by fitting a regression line to the training data, using a technique called maximum likelihood estimation. The line separates the feature space into two regions, corresponding to the two possible outcomes. During the prediction phase, the algorithm calculates the probability of the positive class based on the learned regression line and a new set of input features. If the probability exceeds a certain threshold (usually 0.5), the instance is classified as the positive class; otherwise, it is classified as the negative class.
2. Naïve Bayes
Naive Bayes is a classification algorithm that is based on the Bayes’ theorem. It is widely used for text classification tasks, spam filtering, sentiment analysis, and other applications where the input data consists of categorical or discrete features.
The algorithm is termed “naive” because it simplifies the classification problem by assuming that all features are conditionally independent of each other given the class label. Despite this naive assumption, Naive Bayes often performs well in practice and can be very efficient for large datasets.
The Naive Bayes algorithm calculates the probability of each class given a set of input features and then predicts the class with the highest probability. It utilizes Bayes’ theorem, which describes the relationship between the conditional probability of an event and its prior probability. In the context of Naive Bayes, it calculates the posterior probability of each class given the input features.
To build a Naive Bayes model, the algorithm learns the prior probabilities of each class from the training data. It also estimates the conditional probabilities of the features for each class. During the prediction phase, the algorithm applies Bayes’ theorem to calculate the posterior probabilities and assigns the class with the highest probability as the predicted class.
It can handle high-dimensional datasets with many features, and its assumption of feature independence makes it particularly suitable for text classification tasks. However, this assumption can be a limitation if the features are correlated in reality.
3. Decision Tree
A decision tree is a popular machine learning algorithm used for both classification and regression tasks. It creates a flowchart-like structure which resembles a tree, to make decisions based on input features.
The algorithm works by recursively partitioning the feature space into subsets based on the values of different features. It selects the most informative feature at each step to split the data to maximize the separation between different classes or minimize the variability within each subset.
Starting from the root node, the decision tree algorithm evaluates the feature conditions and assigns data points to subsequent nodes based on their feature values. This process continues until a stopping criterion is met, such as reaching a maximum depth or a minimum number of data points in a node.
Each internal node of the tree represents a decision based on a specific feature which lead to different branches. The leaf nodes, also known as terminal nodes, represent the final decision or prediction for a given input.
During the training phase, the decision tree algorithm learns the optimal feature splits by analyzing the training data.
Once the decision tree is built, it can be used to make predictions for new instances by traversing the tree based on the feature values of the input data. The final prediction is determined by the majority class in the leaf node reached by the input instance.
Decision trees have several benefits, including their interpretability, as the flowchart-like structure allows for easy understanding of the decision-making process. They can handle both numerical and categorical features and can capture complex relationships between variables.
4. Support Vector Machine
A Support Vector Machine (SVM) is a powerful machine learning algorithm used for both classification and regression tasks. It is particularly effective in cases where the data has complex relationships and requires a clear separation between classes.
The primary goal of an SVM is to find a hyperplane in a high-dimensional feature space that best separates the data points belonging to different classes. This hyperplane acts as a decision boundary, maximizing the margin, which is the distance between the closest data points of different classes.
The key idea behind SVM is to transform the input data into a higher-dimensional space using a kernel function. In this transformed space, the SVM seeks to find an optimal hyperplane that achieves the best separation between the classes.
During the training phase, the SVM algorithm identifies support vectors, which are the data points closest to the decision boundary. These support vectors play a crucial role in determining the optimal hyperplane. The algorithm adjusts the position and orientation of the hyperplane to maximize the margin and minimize the classification errors.
Once the SVM is trained, it can classify new instances by mapping them into the feature space and determining which side of the decision boundary they fall on. The SVM assigns the class label based on the side of the hyperplane the data point lies.
Applications of SVM are in different fields, including text classification, image recognition, bioinformatics, and finance.
5. Random Forests
Random Forest is ensemble machine learning algorithm that combines multiple decision trees to make predictions. It is known for its robustness in handling both classification and regression tasks.
The algorithm constructs an ensemble, or a collection, of decision trees by training each tree on a different subset of the training data and a random subset of the input features. Each decision tree independently makes predictions, and the final prediction is determined through a voting or averaging mechanism.
Random Forest introduces randomness in two key aspects. First, during the construction of each decision tree, a random subset of the training data, known as bootstrap samples, is selected with replacement. This technique, called bagging, introduces diversity and helps reduce overfitting.
Second, at each node of the decision tree, a random subset of features is considered for splitting, typically referred to as feature subsampling. By randomly selecting a subset of features, Random Forest introduces further variability and prevents certain features from dominating the decision-making process.
Random Forest has many benefits. It can handle high-dimensional data with many features and is resistant to overfitting. It can handle both categorical and numerical features, and it provides an estimate of feature importance.
6. Stochastic Gradient Descent
Stochastic Gradient Descent (SGD) is an optimization algorithm commonly used in machine learning for training models, particularly in case of large datasets. It is a variant of the Gradient Descent algorithm that offers computational efficiency by updating model parameters using a random subset of the training data at each iteration.
The basic idea behind SGD is to iteratively adjust the model parameters to minimize a given loss function. Instead of considering the entire training dataset in each iteration, SGD randomly selects a small batch, known as a mini-batch, of training examples. This mini-batch is used to compute the gradient of the loss function with respect to the model parameters.
The gradient represents the direction of steepest ascent in the loss function’s space, indicating how the parameters should be adjusted to reduce the loss. In SGD, the model parameters are updated based on this gradient estimate, using a learning rate that controls the size of the updates.
By repeatedly sampling mini-batches and updating the parameters, SGD gradually converges towards a minimum of the loss function, hopefully reaching a good solution for the learning task.
SGD has many advantages. It is computationally efficient, particularly when dealing with large datasets, as it operates on subsets of the data instead of the entire dataset. It is suitable for online learning scenarios where new data arrives continuously, as it can update the model incrementally.
7. K-Nearest Neighbors (KNN)
The K-Nearest Neighbors (K-NN) algorithm is a non-parametric method that makes predictions based on the similarities between the input data points.
The K-NN algorithm operates on a training dataset with labeled instances. During the training phase, the algorithm simply stores the data points and their corresponding labels.
When a new, unlabeled instance needs to be classified or predicted, the K-NN algorithm compares it to the labeled instances in the training set. It measures the similarity between the new instance and the existing instances using a distance metric, commonly the Euclidean distance.
The “K” in K-NN refers to the number of nearest neighbors to consider for making predictions. K is a hyperparameter that needs to be specified beforehand. The algorithm identifies the K nearest neighbors of the new instance based on the distance metric.
For classification tasks, the K-NN algorithm assigns the class label to the new instance based on the majority vote of its K nearest neighbors. The class that appears most frequently among the neighbors is considered the predicted class for the new instance.
The algorithm’s main drawback is its computational complexity, especially for large datasets, as it requires calculating the distances between the new instance and all training instances.

More to read
- Artificial Intelligence Tutorial
- Types of Machine Learning
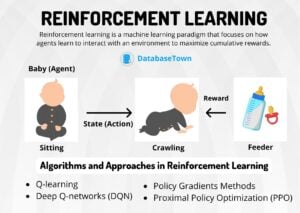
- Supervised Learning
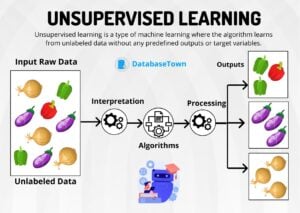
- Unsupervised Learning
- Artificial Intelligence VS Machine Learning
- Machine Learning Interview Questions
- Best Udacity Courts for Machine Learning
- Best Books on AI and Machine Learning
- Best Laptops for AI and Machine Learning