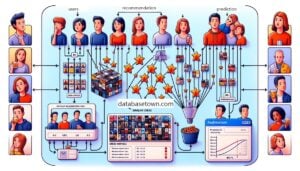
What is Big Data Analytics? How it Works?
Big data analytics refers to the advanced analytical techniques used to figure out actionable insights, correlations and trends from large, diverse datasets exceeding the processing capacity of traditional data analysis tools. Big data analytics enables data-driven decision making to derive competitive advantage by revealing patterns and opportunities hidden within massive datasets,.
The Promises and Challenges of Big Data
Big data holds the promise of catalyzing innovation across business, government and science because untapped insights with immense potential value are hidden within vast datasets. However, realizing value from big data is extremely challenging due to the huge volume, velocity and variety of structured, semi-structured and unstructured data that overwhelms traditional storage, processing and analysis approaches.
Getting maximum value from big data necessitates a completely new data processing stack designed specifically to handle staggering data volumes, relentless data velocity, and extensive data diversity.
The big data analytics toolkit must deliver scalable storage, high performance distributed processing, advanced analytics algorithms, predictive modeling, compelling visualizations and more. Many open source and commercial technologies have emerged to tackle these big data analytics challenges and turn promises into reality.
Here is a detailed article on “How Big Data Analytics Works” with each heading expanded to at least 300 words:
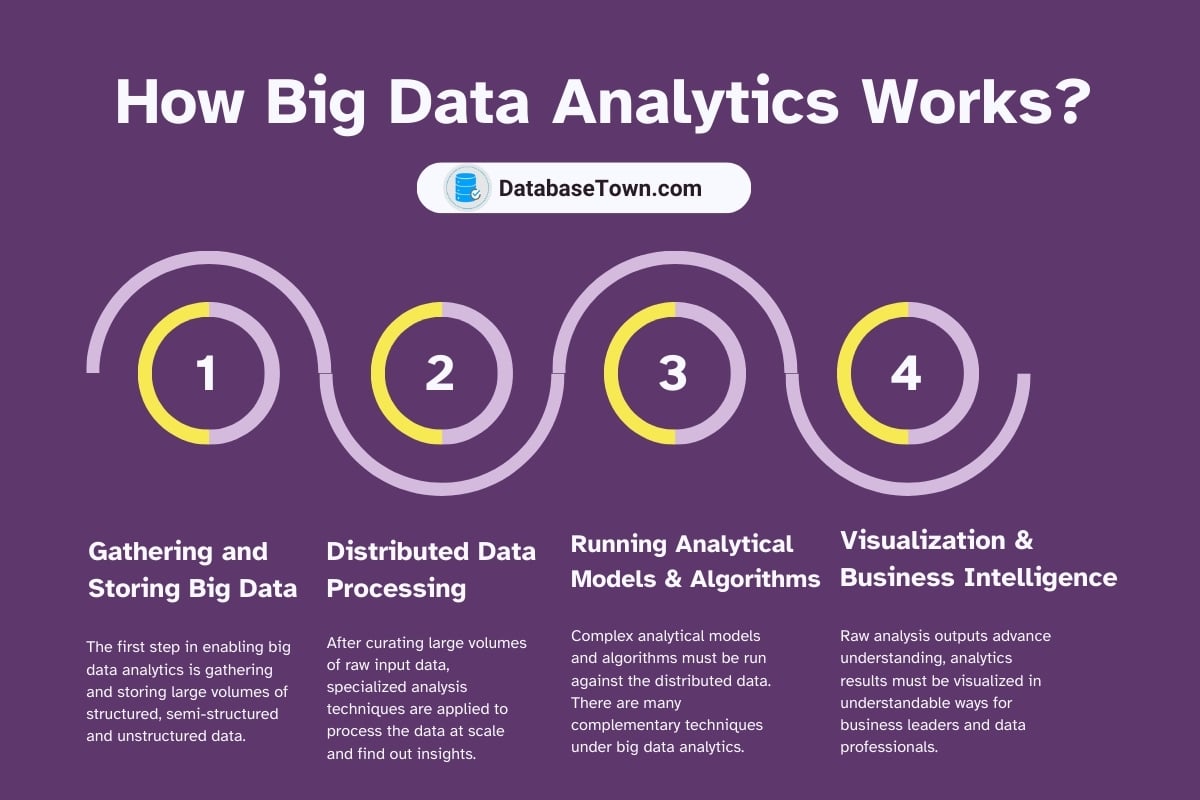
How Big Data Analytics Works
These are the main steps of big data analytics. Together these capabilities enable organizations to continuously transform tide of big data into an information-rich asset powering analytics across the business.
Gathering and Storing Big Data
The first step in enabling big data analytics is gathering and storing large volumes of structured, semi-structured and unstructured data. This raw big data comes from many different sources including operational databases, Internet of Things sensors, mobile apps, social media platforms, finance systems, multimedia files, and more.
Specialized tools and distributed systems like Hadoop, NoSQL databases, and cloud-based data lakes provide scalable storage and data handling capabilities for accumulating these massive, diverse datasets.
Pre-processing tasks like cleansing, transforming and organizing raw data also occurs to make downstream analytics easier. Robust IT infrastructure across servers, high-bandwidth networks and petabyte-scale storage arrays makes the reliable collection of big data at scale possible.
A capable “data ingestion pipeline” is necessary to gather huge amounts of raw data into specialized repositories optimized for analytics.
Distributed Data Processing
After curating large volumes of raw input data, specialized analysis techniques are applied to process the data at scale and find out insights. Key enabling technologies include massively parallel processing (MPP) architectures, which partition computation tasks across clusters of commodity servers to enhance performance and throughput.
Apache Hadoop provides distributed filesystems like HDFS along with the MapReduce programming framework for optimizing data analysis workloads across compute clusters. Other engines like Apache Spark speed up batch, streaming, machine learning and graph analytics workloads with in-memory caching and processing acceleration capabilities over data in distributed stores. Distributed processing system partition big data computation tasks to run concurrently across multiple servers, accelerating the analysis.
Running Analytical Models and Algorithms
Utilizing raw processing power alone does not yield insights. Complex analytical models and algorithms must be run against the distributed data. There are many complementary techniques under big data analytics.
Data mining algorithms automatically comb through data. They dig up statistical correlations and interesting patterns not easily visible. Machine learning systems are included as well. These systems utilize classification models, clustering models, forecasting and predictive models. These models train on historical examples to find key relationships.
Graph and network analysis maps relationships between people, products, locations and other entities. Text mining and natural language processing extract meaningful semantics and insights from unstructured text data. Geo-spatial analysis connects location-based signals to reveal trends. Specialized algorithms detect anomalies, significant changes and similar events of interest.
All these techniques analyze processed data through intelligent models. This analysis powers the desired analytical insights.
Visualization and Business Intelligence
Raw analysis outputs advance understanding, analytics results must be visualized in understandable ways for business leaders and data professionals. Big data visualization tools help convey critical findings, metrics and KPIs through compelling interactive dashboards, reports and charts that bring insights to life and promote data-informed decision making and clear communication.
Integrating big data outputs into familiar business intelligence and analytics platforms makes analysis consumable, measurable, and actionable from individual laptop screens to large dashboard displays in enterprise command centers.
Advanced visualization further enables deeper exploratory analysis. Big data analytics connectivity to BI tools closes the loop to convert raw data into usable business intelligence.
Features of Big Data Analytics
Big data analytics is distinguished from traditional business data analytics in three key ways:
Bigger Datasets
Big data analytics handles terabytes to exabytes of highly diverse and often messy data from sensors, devices, social media, documents, audio, video, etc. far larger than conventional operational databases and business intelligence systems. This requires distributed systems on commodity hardware to achieve affordability. On-premises and cloud-based data lakes have emerged to economically store huge datasets with great flexibility.
Continuous Data Streams
Endless flows of streaming data from sensors, server logs, mobile devices, social platforms and other sources require continuous analytics rather than sporadic analysis. This real-time analytics necessitates specialized big data analytics architecture for throughput, low latency and scalability to keep pace with firehoses of data in motion.
Advanced Analytics Methods
The volume and variety of big data allows advanced analysis like machine learning, predictive analytics, data mining, text mining, statistical modeling, and natural language processing to find insights traditional techniques could not reveal given data limitations. Big data analytics utilizes these methods.
So paradigm shifts around data volume, velocity and analytical sophistication set big data analytics apart from old school business intelligence.
Value of Big Data Analytics Across Industries
Big data analytics has become indispensable in driving innovation, efficiencies, growth and competition across nearly every industry. Here are some major examples:
Insurance – Analysis of risk factors and claims data allows accurate premium pricing customized to unique customer attributes and needs while reducing fraud. Customer churn is predictable leading to proactive retention programs.
Healthcare – Patient clinical records and genomic data combined with public health datasets reveals health outcomes correlations helps in personalized medicine, clinical trial optimizations and pandemic preparedness.
Retail – Clickstream analysis optimizes merchandising tactics leading to cross-selling. Sentiment analysis guides product/service enhancements adept to preferences.
Automotive – Sensor data produces insights on product usage, performance and drivers behavior improving design, maintenance, safety and manufacturing quality.
Banking – By analyzing financial transactions, credit bureau data and customer demographics in real-time, precarious accounts, application scoring and tailored offerings improve while reducing loan default risks and fraud.
Architectural Framework to Support Big Data Analytics
To support continuous workflows where vast data volumes flow smoothly from initial ingestion to advanced analytics and meaningful insights requires an end-to-end architectural framework covering:
Robust Data Pipeline – A data pipeline sprawls self-service data across the enterprise. This spans batch/real-time data ingestion framework, data catalog that accesses internal data, external data, data warehouse, data lake, and data delivery system.
Scalable Storage – Distributed storage cost-effectively scales across commodity servers to handle multiple data formats and immensities without compromising performance. HDFS, NoSQL databases, distributed file/object stores underpin big data analytics architectures.
High Performance Processing – Parallel programming standards embedded in Hadoop, Spark and SQL-on-Hadoop engines rapidly process huge, streaming datasets by distributing compute-intensive work across clusters of computers.
Analytics Sandbox – A cloud-based or on-premises sandbox helps in data exploration and combine data preparation, discovery and interactive analytics without affecting production environments. It supports iterative data experimentation.
Business Intelligence – Big data powers traditional business metrics, dashboards and reports expanded by advanced analytics like predictions, simulations and optimizations that transform decision automation and ROI.
Real-World Applications of Big Data Analytics
Here are some examples of big data analytics that are delivering concrete business value in different areas.
Customer Intelligence – By combining transaction activity with customer communications and satisfaction metrics, multi-channel profiles filled with granular behavioral attributes support micro-segmentation, highly personalized engagements, recommendations and predictive churn modeling.
Sensor-Driven Predictive Maintenance – IoT generates machine sensor data tracking usage, temperature, humidity and other telemetry. Combined with ML algorithms, predictive models forecast equipment failures and recommend maintenance optimizing uptime.
Supply Chain Optimization – Analysis of sourcing costs, logistics sensors tracking shipment routes, weather, traffic, point of sale data, inventory metrics and other supply chain data powers dynamic optimization of networks for efficiency.
Content Recommendations – Based on previous browsing, ratings and purchase data, product affinity analytics deliver personalized recommendations to engage customers via custom content improving conversion rates and satisfaction.
Fraud Prevention – By applying machine learning techniques to transaction streams to detect outlying patterns in real-time, banks spot precarious transactions early and take action that reduces retail banking fraud 7% year-over-year.
Key Points on Big Data Analytics
Here are the main reasons business and technology leaders should recognize the big data analytics:
- Big data analytics deciphers immense hidden value – raising revenue, reducing cost and enhancing processes when grounded in business strategy.
- To tap into its full potential requires an integrated, scalable and flexible end-to-end architecture from data ingestion to decision automation.
- Big data analytics necessitates statistical, technical and business skills working in harmony across teams – technologists, data engineers, quantitative analysts and business leaders.
- Ongoing tuning, measurement and learning ensures maximum ROI as tools and techniques continually advance.
The big data analytics wave is still rising. Organizations proactively embracing this complex capability will ride this wave to new heights of market leadership.
Related posts
- Big Data Main Concepts
- Big Data Programming Languages
- Can Big Data Predict The Future?
- Can I Learn Big Data Without Java?
- Can Big Data Protect A Firm From Competition?