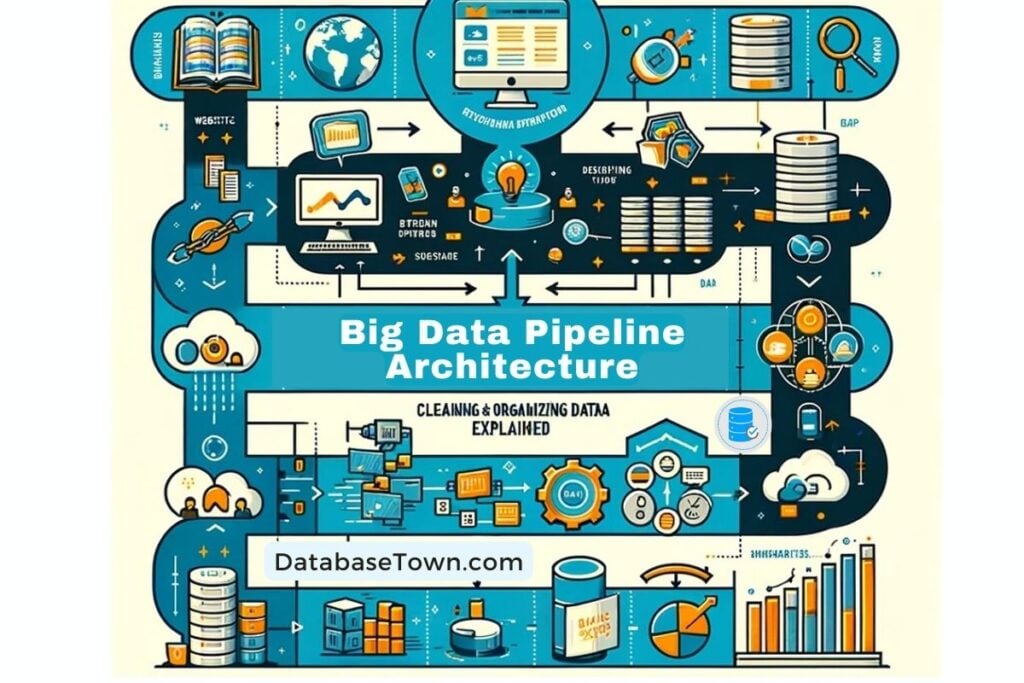
Big Data Pipeline Architecture
Big Data Pipeline Architecture Explained:
In summary, a big data pipeline is like a factory assembly line for data. It takes raw data, processes it into a useful form, stores it, analyzes it for insights, and then presents it in an understandable way.
- What It Is: A big data pipeline is a set of steps or processes that move data from one system to another.
- Purpose: Its main goal is to gather, process, and analyze large amounts of data efficiently.
- Components:
- Data Collection: Gathering data from different sources like websites, apps, sensors, etc.
- Data Processing: Cleaning and organizing the data into a usable format.
- Data Storage: Keeping the processed data in databases or data warehouses.
- Data Analysis: Using tools to understand the data, find patterns, and make decisions.
- Data Visualization: Presenting the data in charts or graphs for easier understanding.
Importance of Big Data Pipeline Architecture
Before plunging into the technical intricacies, it is pivotal to comprehend why Big Data Pipeline Architecture holds such prominence. In the relentless pace of business operations, colossal datasets are generated on a daily basis.
Without an effective data processing system, this treasure trove of information remains untapped. A meticulously architected Big Data Pipeline not only ensures seamless data accessibility but also empowers real-time analysis, thereby fostering well-informed decision-making.
Components of Big Data Pipeline Architecture
i. Data Collection or Data Ingestion
The initial phase of any data pipeline involves the ingestion of raw data. This process encompasses the collection of data from diverse sources such as databases, sensors, and logs. Prominent tools for data ingestion include Apache Kafka and Apache Flume, playing a pivotal role in the initial stages of the data processing journey.
ii. Data Processing
The subsequent stage in the pipeline is dedicated to cleaning, transforming, and aggregating raw data into a format conducive to analysis. Apache Spark and Apache Flink emerge as stalwarts in large-scale data processing, offering parallel and distributed computing capabilities that are fundamental to efficient data processing.
iii. Data Storage
Following the ingestion phase, the data requires a reliable storage solution. Choices for Big Data storage abound, with options like the Hadoop Distributed File System (HDFS) and Amazon S3 taking the lead. The selection often hinges on specific business requirements, each option possessing its unique strengths.
iv. Data Analysis
Armed with processed data, businesses can leverage tools such as Apache Hive, Apache HBase, or Apache Impala to query and analyze data. This phase is indispensable for extracting valuable insights and identifying patterns that can inform strategic decision-making.
v. Data Visualization
The final frontier involves presenting the analyzed data in a coherent and comprehensible manner. Tools like Tableau, Power BI, or Apache Superset serve as instrumental aids in creating interactive and insightful visualizations, making complex data accessible to a broader audience.
Best Practices in Big Data Pipeline Architecture
i. Scalability
A fundamental aspect of designing a robust architecture is scalability. As data volumes burgeon, the pipeline should seamlessly expand to accommodate increased loads. Cloud-based solutions, exemplified by AWS and Azure, provide elastic scalability, allowing resources to scale dynamically based on demand.
ii. Fault Tolerance
Ensuring the resilience of the pipeline is paramount to sustaining continuous data flow, even in the face of hardware failures or other challenges. Implementation of redundancy and backup mechanisms becomes indispensable to preempt data loss and maintain operational integrity.
iii. Security
Data security stands as a cornerstone in the realm of Big Data Pipeline Architecture. Employing encryption techniques during data transmission and storage is imperative. Establishing stringent access controls, coupled with regular audits and monitoring of data access, fortifies the security posture of the entire pipeline.
iv. Monitoring and Logging
To maintain the health and performance of the pipeline, robust monitoring and logging mechanisms are indispensable. Tools such as Prometheus or the ELK stack (Elasticsearch, Logstash, and Kibana) play a pivotal role in identifying and promptly addressing issues, ensuring the sustained efficiency of the data processing pipeline.
Example of a Big Data Pipeline:
Imagine a shopping website:
- Data Collection: The website collects data about what customers view, click, and buy.
- Data Processing: This data is cleaned (removing errors or irrelevant parts) and organized.
- Data Storage: The processed data is stored in a database.
- Data Analysis: The company uses this data to understand shopping trends, like which products are popular.
- Data Visualization: They create charts to show which products are selling the most.
In the contemporary landscape of information abundance, businesses and organizations grapple with the challenge of managing colossal datasets. To use the potential locked within this sea of information, a resilient infrastructure becomes imperative.
This is where the significance of Big Data Pipeline Architecture comes to the forefront. This article is a comprehensive exploration of the intricacies involved in crafting an efficient Big Data Pipeline, with a specific focus on its importance, constituent elements, and optimal methodologies.
In conclusion, the landscape of Big Data necessitates a meticulous and well-thought-out approach to data processing. By understanding the pivotal role of Big Data Pipeline Architecture, businesses can unlock the latent potential within their datasets, fostering a culture of data-driven decision-making and propelling sustainable growth in the digital age.
More to read
- Big Data Main Concepts
- Big Data Programming Languages
- Can Big Data Predict The Future?
- Can I Learn Big Data Without Java?
- Can Big Data Protect A Firm From Competition?